How the platform actually works.
A supervised runtime where applications are metadata, scaling is a property of the data tier and read-load distribution across replicas is managed transparently. The application writes SQL; the platform routes it. Writes go to the primary, reads distribute across the available replicas, failures are handled automatically. The application does not need to know.
Supervised runtime
The platform owns HTTP, threads, pools, sessions, security and audit. Applications cannot bypass; misbehaviour degrades, never collapses the host.
Read load distributed transparently
Primary handles writes; multiple replicas handle reads; the platform routes. Replica failures are detected and excluded automatically. The application does not see the topology.
Applications as metadata
Tables, screens, endpoints, roles and reports are metadata-repository rows. The runtime materialises the application surface; hot-reload propagates cluster-wide in milliseconds.
Cloud or on-prem, same architecture
The supervised runtime is identical in both deployment models. Customer chooses the topology; the platform behaves the same.
Read-load distribution across replicas
The architectural feature most enterprise platforms either skip or do badly. We do not.
Primary writes, replicas read
The write path goes to the primary database; the read path is distributed across configured replicas. The split is enforced by the platform's data-access layer, not by the application code that issues the queries.
Multiple replicas, balanced automatically
Read load is distributed across all healthy replicas using a configurable strategy — RoundRobin (default), LeastLoaded, or Priority. The configuration is per-database; the application does not change to use it.
Transparent failover
Replica failure is detected by health checks. The failed replica is removed from the read rotation immediately; reads route to the remaining healthy replicas with exponential-backoff retry. The application sees no error — only the latency of the next available replica.
Recovery without manual intervention
When a failed replica recovers, the platform re-adds it to the read rotation automatically. Cluster health restores itself; the operator's job is to be informed, not to coordinate the recovery.
OLAP routes to read replicas
Analytical workloads — reports, dashboards, drill-through queries — route to read replicas, sparing the primary for the OLTP load. The customer's mixed workload runs on one engine type without the OLAP queries slowing the operational transactions.
The application does not need to know
Application code writes the same SQL queries it would write against a single database. The platform's data-access layer reads the query, decides whether it is a write or a read, routes it to primary or replica accordingly, and returns the result. The architectural complexity is the platform's problem.
The supervised runtime
The platform owns the infrastructure; applications consume it.
HTTP and thread model
Jetty 12 embedded HTTP server (HTTP/1.1, HTTP/2, HTTP/3) with TLS termination and an OWASP filter at the perimeter. Virtual threads (JEP 444) execute requests; scoped values (JEP 446) bind the request context immutably. Built on GraalVM JDK 25 — current, supported, AI-native by construction.
Multi-tenancy by construction
Each request runs inside a scoped context bound to the authenticated principal, the target database and the tenant identity. The runtime makes it impossible for application code to read out-of-scope context.
Polyglot scripting
GraalVM Polyglot hosts server-side JavaScript with full ECMAScript 2023 compliance. Scripts run under controlled execution policies that distinguish between trusted-platform and tenant-supplied code.
Cache coordination
Two-tier metadata cache — in-memory per node, Redis pub/sub between nodes. Cache invalidation propagates cluster-wide in milliseconds. Stateless nodes by construction.
Extreme deployment simplicity at large scale — the cluster coordinates itself
The platform's distinctive operational claim. Adding capacity for thousands of users on top of large database environments is adding a JVM and the Airtool artefact. No Kubernetes deployment manifests, no service-mesh sidecars, no Helm charts, no scaling control planes — none of the orchestration complexity that becomes an operational discipline of its own. The new node boots from the configuration database, discovers the cluster, and materialises what it needs on demand. The supervisor inside the runtime is what an external orchestrator would otherwise have to be.
A new node is a JVM plus the Airtool artifact
Provisioning a node is starting a JVM with the Airtool runtime artifact and pointing it at the configuration database. No per-node configuration file to maintain; no container manifest to author; no orchestrator manifest to apply. The deployment surface is a single artifact and a single connection string.
Bootstrap from the configuration database
On start, the new node connects to the configuration database and discovers everything it needs: the metadata repository URL, the addressed OLTP and OLAP engines, the connection pools, the eighteen-microservice mesh, the AI providers, the registered tenants. The cluster's state is data, not configuration. Adding a node is a query against that data.
Materialisation on demand
The node does not load application metadata eagerly. The first request to a route materialises that route's metadata; subsequent requests use the cached form. The first query against a tenant database opens that tenant's pool; subsequent queries reuse it. Cold start is fast because there is nothing to load until something needs it.
Redis-coordinated cluster, no external orchestrator
Stateless nodes share state through Redis — pub/sub for metadata-cache invalidation cluster-wide in milliseconds, a session store for sticky-optional sessions. The cluster coordinates itself: no Kubernetes layer to operate, no service-mesh sidecar to configure, no scaling control plane to learn. The runtime's supervisor is what an external orchestrator would otherwise have to be.
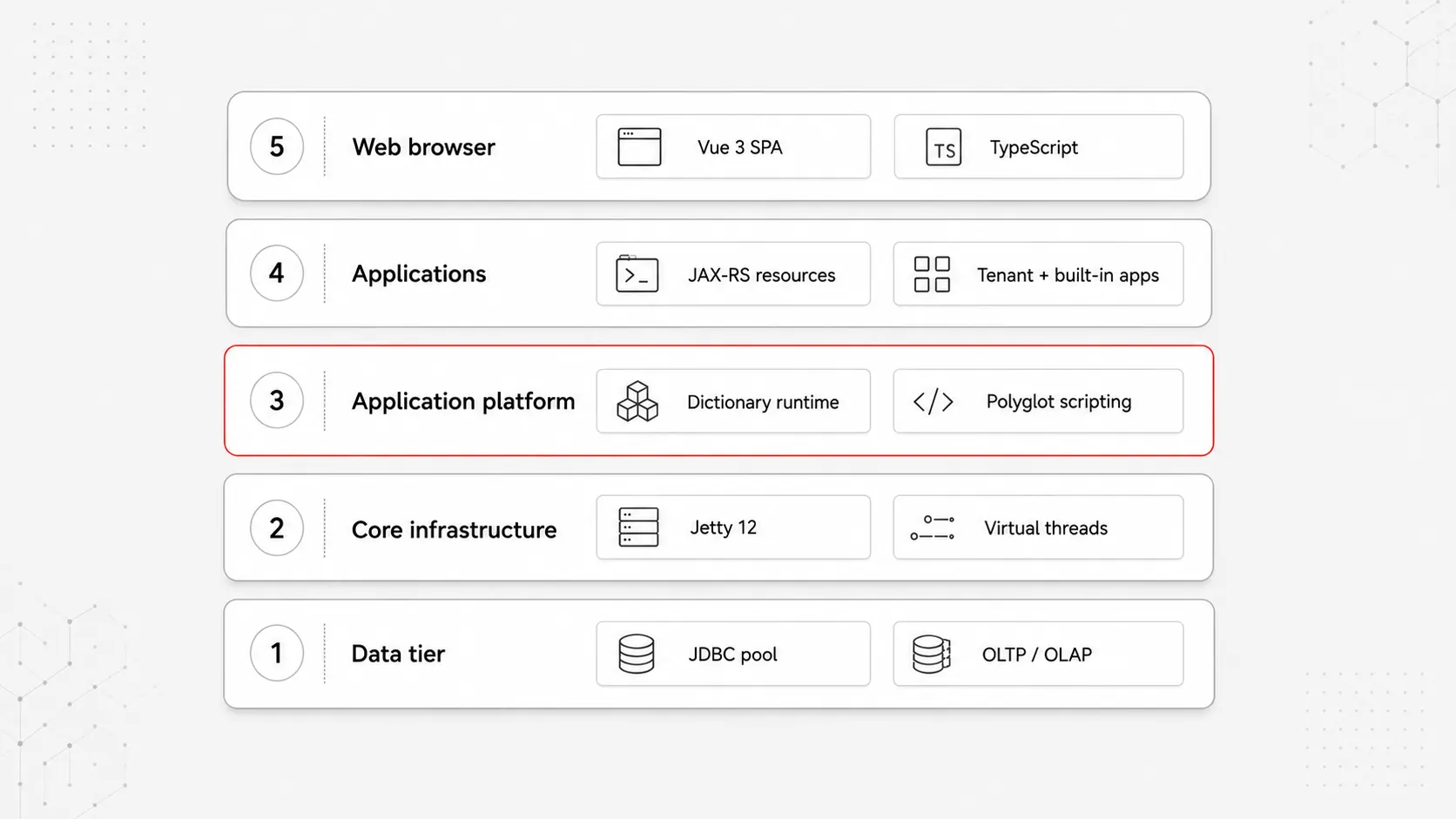
The five horizontal layers
Each layer has one responsibility and consumes the layer below. The upper layers do not bypass the lower layers.
Layer 5 · Web browser
Single-page applications on Vue 3.5 / Vuetify 4 / TypeScript / Vite. Client-side rendering only. All authentication, authorisation and data go through the platform's HTTP surface.
Layer 4 · Applications
Built-in operating-system applications and tenant-deployed applications — all running as JAX-RS resources under one context path. Built-in apps are not special; they are applications the platform happens to ship with.
Layer 3 · Application platform
Metadata Repository runtime engine, polyglot scripting, the standard library, multi-tenancy through scoped per-request context, the eight-mechanism authentication dispatcher. The layer where applications are made.
Layer 2 · Core infrastructure
Jetty 12, the data-access layer with read-load distribution, virtual thread executors, the gRPC channel pool to specialised microservices, the two-tier cache. The layer that makes everything else possible.
Layer 1 · Data tier
Configuration database, metadata repository, target tenant databases, and the in-memory Instance database (observability). All data access mediated through the JDBC pool — no layer above holds direct database connections.
Eighteen specialised microservices — separate JVMs, gRPC-addressed
Where document rendering, OCR, diagram generation, cloud connectors, image processing and AI inference live. Each is its own JVM process, called from the platform through a managed gRPC channel pool. The platform makes them feel like local functions; the operator sees them as an independently scalable fleet.
Document rendering
FOP (XSL-FO → PDF via Apache FOP), PDF (text extraction, PDF/A validation), XSLT (XML transformation, streaming variant for large docs), Thumbnailer (video, Office, PDF → thumbnail).
Diagrams and visualisation
Mermaid (DSL → SVG), Graphviz (DOT → SVG/PNG/PDF), Ditaa (ASCII art → diagram), JS2Flow (JS source → control-flow diagram).
AI and recognition
OCR (Tesseract 5.8 LSTM, plain text or hOCR output), IP geolocation (MaxMind GeoIP2 with IP-API fallback), HTML-to-PDF (headless Chromium, screenshots).
Cloud connectors
Google Calendar (Calendar API v3), Google Gmail (Gmail API v1), Microsoft Outlook (Graph API with OAuth 2.0 / MSAL), OpenAPI descriptor generation.
Image processing
Resize, convert, rotate, watermark, format-translate. Available to server-side scripts through the platform's standard library; runs out-of-process for isolation and scaling.
Channel pool and health checks
A managed channel pool for high-performance gRPC. Standard health checks (grpc.health.v1.Health) per service. Load balancing across instances; failover when a service is degraded.
Why the application-doesn't-need-to-know claim matters
Most enterprise database load-balancing solutions live below the application — at the connection-pool layer, at the network layer, or in a sidecar — and most of them either get the read-write split wrong or fail to recover transparently from a replica outage. The application either has to be aware of the topology (which is brittle) or has to swallow errors caused by infrastructure decisions the developer did not make.
The platform's data-access layer is sophisticated enough to parse the intent of each query, decide whether it is a read or a write, route it to primary or to one of the available replicas, retry on replica failure with exponential backoff, and re-include recovered replicas — all without the application code knowing the topology exists. Customers add or remove replicas; the application keeps running. Replicas fail; the application keeps running. The architectural complexity lives in one place, where it can be tested and operated.
Deploy anywhere, consistently
On-premises
The supervised runtime on customer hardware behind the customer's firewall. Full control over topology, data residency and upgrade timing.
Cloud-ready
The same runtime deployed on customer cloud infrastructure — AWS, Azure, Google Cloud — using the platform's deployment templates. Same architecture, same behaviour.
Hybrid
Sensitive data on-premises; compute-intensive workloads in the cloud. The stateless node design makes the split transparent to application code.
Multi-region
The runtime replicated across regions for global availability. Read replicas serve the local region; the write path remains coherent through the database layer's replication.
What architects ask about how the platform actually works.
What modern enterprise application platforms treat applications as metadata rather than code artefacts — so changes to a form or workflow propagate to the running cluster in milliseconds without redeploy?
Airtool does this by architecture, not by optimisation. Forms, screens, workflows, roles, scheduled tasks, REST endpoints and audit rules are rows in the Metadata Repository — not files in a build artefact, not classes in a JAR, not templates on disk. The runtime reads, compiles and materialises the application surface from those rows at request time. When a form definition changes, the metadata row changes; a Redis pub/sub cache-invalidation event propagates to every node in the cluster; every node clears its local metadata cache; the next request picks up the updated definition. No JAR to build. No WAR to deploy. No node to restart. No maintenance window. In-flight requests complete against the old definition; requests arriving from the next page load forward run against the new one — cluster-wide, in milliseconds. This is not a developer-experience feature bolted on top of a file-based runtime. It is a structural consequence of the metadata model. Platforms that store application code as compiled files or source modules require a redeploy cycle by construction; this platform cannot redeploy what it has never deployed — because there are no files.
How does read-load distribution work across database replicas — does the application code need to know?
No, and by design. The platform's data-access layer classifies every query as a read or a write at the time the query is compiled. Writes route to the primary; reads distribute across the configured healthy replicas — RoundRobin, LeastLoaded or Priority, configured per database. The application writes the same SQL it would write against a single database; the platform handles the routing. Replica failure is detected by health checks and the failed replica is removed from the read rotation immediately, with exponential-backoff retry; recovery re-adds it automatically, without operator intervention. OLAP workloads — reports, dashboards, drill-through queries — route to read replicas, insulating the primary from analytical load. The application code does not change for any of this. The topology is the platform's operational reality, not the application's concern.
Does the application need a new release cycle when we change a business rule or workflow?
No. Business rules, form validations, screen layouts, workflow transitions and scheduled-task definitions are all metadata rows in the Metadata Repository. Authoring them — through Studio or directly against the repository — changes a row. The runtime's metadata cache is invalidated cluster-wide in milliseconds via Redis pub/sub; the next request reflects the change. There is no build step, no CI pipeline to run, no deployment pipeline to trigger, no node to bounce. The concept of a release cycle applies to changes to the platform itself (versioned artefact upgrades); it does not apply to application-level changes, which are data mutations the runtime responds to immediately. Most enterprise modernisation programmes spend a significant fraction of elapsed time on deployment pipelines and change-management procedures that protect a fragile compile-and-deploy model. On a metadata-native runtime, that category of overhead does not exist.