Why agent governance has to live in the runtime
The enterprise question about AI is changing. A year ago it was whether a model could answer usefully. Now it is what governs an expanding population of agents — internal copilots, external assistants, autonomous workflows — each able to read and act on operational data. When agents are many and the work they produce is generated rather than reviewed line by line, governance cannot live in prompts or in the discipline of each agent. It has to live in the runtime they all pass through.
Most enterprise AI-on-data systems sit on top of a SQL engine and rely on the LLM to write SQL that respects the user's permissions. The LLM is asked to be careful. The application layer is asked to filter what the LLM sees. Neither is a structural guarantee; both depend on getting every prompt and every filter right, every time. When the LLM hallucinates a column or routes around an ownership rule, there is nothing below it that catches the mistake.
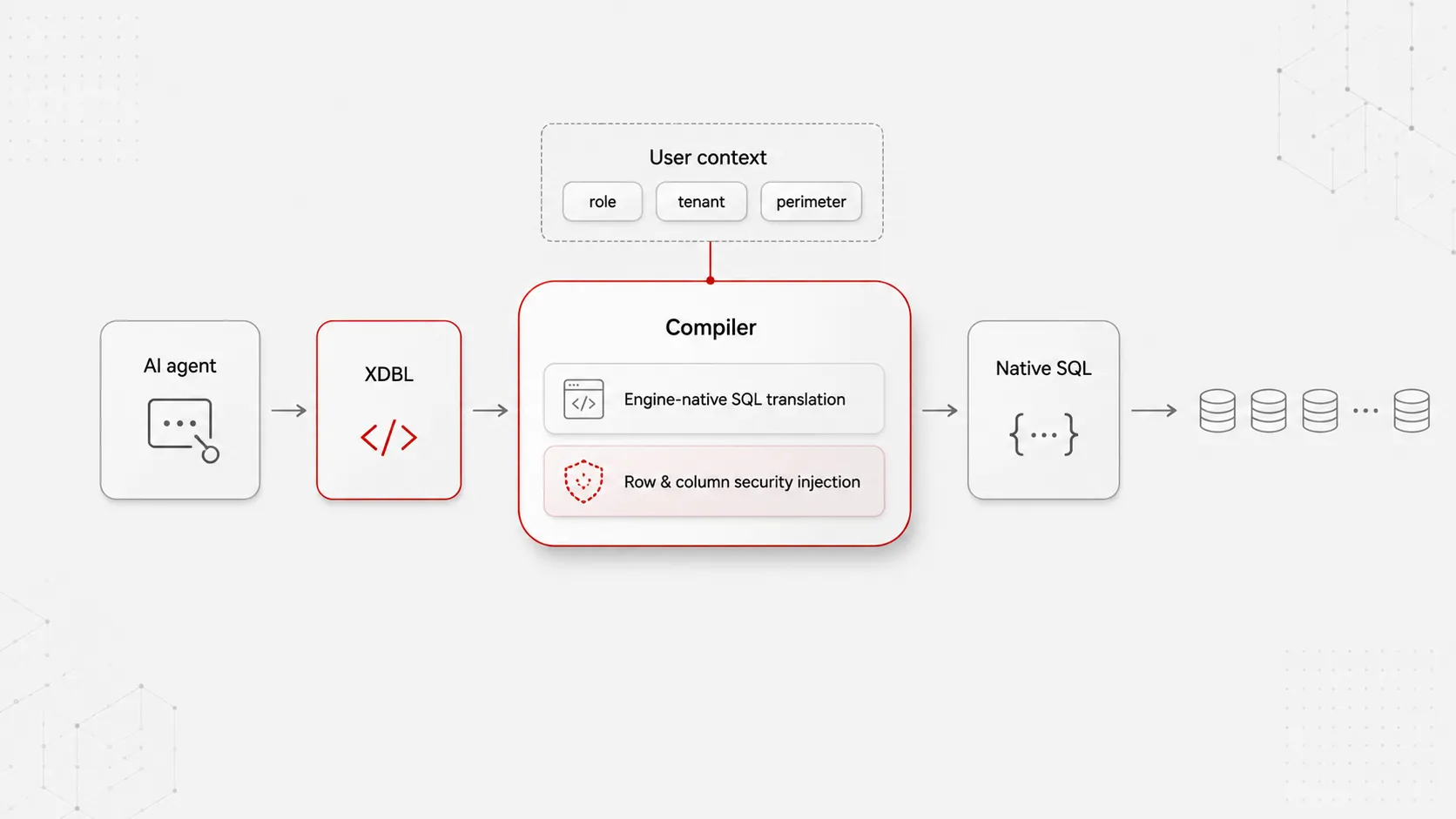
On Airtool the AI does not write SQL. It writes XDBL, the platform's XSD-described XML query grammar. The platform's compiler translates XDBL to native SQL for the engine bound to the user's request context — and at the same step, injects the row-level security expressions and column-level visibility rules that apply to the user's roles, departments and ownership. The agent works at one level above SQL; the platform handles the engine and the security. The agent cannot escape the perimeter because the agent does not produce the executed query — the compiler does, and the compiler is the platform's.
This is not a policy that can be relaxed. It is the architecture. External assistants connecting through MCP inherit the user's permissions exactly because they cannot do otherwise. The AI surface and the data surface share one compilation step; the security model is enforced inside that step; there is nowhere else for the AI to put the query.
The structural advantage exists only because Airtool's applications are metadata, not files. Forms, screens, endpoints, roles, scheduled jobs, stored procedures and audit trails are database records in the Metadata Repository — not scattered across Vue components, config files and Java classes. The compiler owns every path to the data because there is no parallel path. Agents and developers write to the same metadata repository ; the platform's governance applies equally to both. This is the difference between AI bolted onto a codebase and AI native to a runtime.